To use this transformer, you must install the copulas module in addition to rdt. This is available in open source for all users.
pip install rdt[copulas]
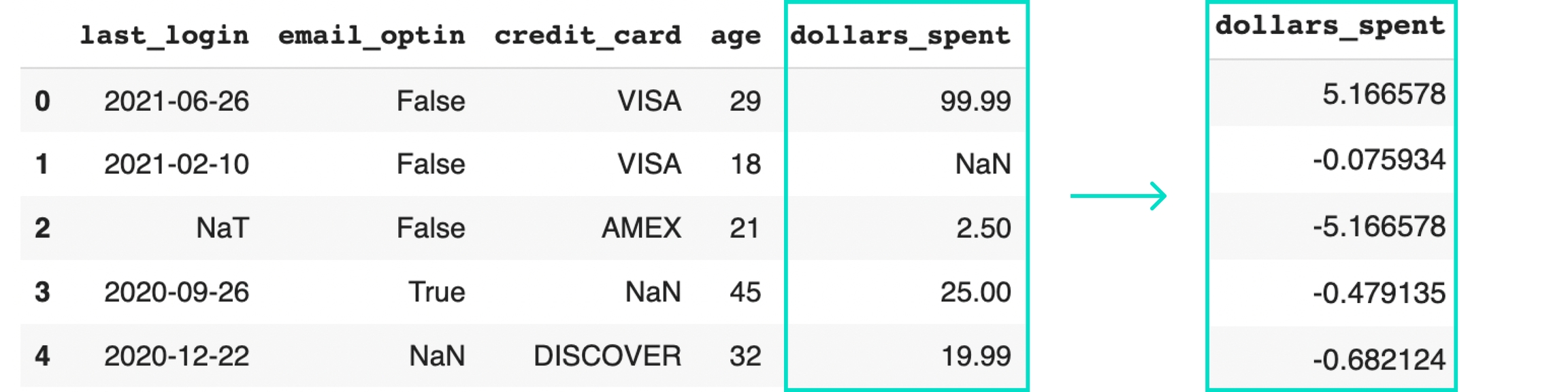
The GaussianNormalizer performs a statistical transformation on numerical data. It approximates the shape of the overall column. Then, it converts the data to a different shape: a standard normal distribution (aka a bell curve with mean = 0 and standard deviation = 1).
from rdt.transformers.numerical import GaussianNormalizertransformer =GaussianNormalizer()
Parameters
missing_value_replacement: Add this argument to replace missing values during the transform phase
(default) 'random'
Replace missing values with a random value. The value is chosen uniformly at random from the min/max range.
'mean'
Replace all missing values with the average value.
'mode'
Replace all missing values with the most frequently occurring value
<number>
Replace all missing values with the specified number (0, -1, 0.5, etc.)
None
Deprecated. Do not replace missing values. The transformed data will continue to have missing values.
(deprecated) model_missing_values: Use the missing_value_generation parameter instead.
missing_value_generation: Add this argument to determine how to recreate missing values during the reverse transform phase
(default) 'random'
Randomly assign missing values in roughly the same proportion as the original data.
'from_column'
Create a new column to store whether the value should be missing. Use it to recreate missing values. Note: Adding extra columns uses more memory and increases the RDT processing time.
None
Do not recreate missing values.
distribution: In the first step of the normalization, the transformer approximates the shape (aka distribution) of the overall column after searching through multiple options. Use this parameter to limit the options it searches through.
(default) 'parametric'
Search through 1-dimensional distributions that have a set number of parameters. This includes: gaussian, gamma, beta, student_t and truncated_gaussian
<name>
Only consider the distribution that is named. Possible names include 'norm', 'gamma', 'beta', 't', 'truncnorm', 'uniform' and 'gaussian_kde'
Deprecated: 'gaussian', 'truncated_gaussian' and 'student_t'. Instead, please use the names 'norm', 'truncnorm' and 't' (respectively).
<copulas.univariate.Univariate>
Use the Univariate object created from the Copulas library. See the User Guide for more information.
enforce_min_max_values: Add this argument to allow the transformer to learn the min and max allowed values from the data.
(default) False
Do not learn any min or max values from the dataset. When reverse transforming the data, the values may be above or below what was originally present.
True
Learn the min and max values from the input data. When reverse transforming the data, any out-of-bounds values will be clipped to the min or max value.
learn_rounding_scheme: Add this argument to allow the transformer to learn about rounded values in your dataset.
(default) False
Do not learn or enforce any rounding scheme. When reverse transforming the data, there may be many decimal places present.
True
Learn the rounding rules from the input data. When reverse transforming the data, round the number of digits to match the original.
FAQ
When should I use this transformer?
Your decision to use this transformer is based on how you plan to use the transformed data. For example, algorithms such as the Gaussian Copula require normalized data. If you're planning to use such an algorithm, this transformer might be a good pre-processing step.
Which algorithm does this transformer use to normalize the data?
This transformer uses a Probability Integral Transform to transform the original data into a uniform distribution. From there, it converts the data to a standard normal (Gaussian) distribution.
Can you define the mathematical terms?
Below are some definitions for the mathematical terms we've used in this doc.
A distribution is mathematical formula that describes the overall shape of data. A distribution has parameters that precisely describe it. For example a bell curve is a distribution with parameters for mean and standard deviation.
A parametric distribution is a distribution that has a preset number of parameters with specific meanings. For example, a bell curve is a parametric distribution because we know it has 2 parameters (mean and standard deviation)
A gaussian or standard normal distribution is a bell curve with mean = 0 and standard deviation = 1. Other distribution names such as gamma, beta and student t have precise meanings. Refer to this list of probability distributions for more info.
How does the distribution parameter affect the transformation?
The GaussianNormalizer approximates the column's shape (aka distribution) by searching through multiple options. The more accurate the approximation, the better the accuracy. However, there is a tradeoff between accuracy and the transformation time.
Searching through more distributions takes a longer time but leads to greater accuracy. To save time, you can input a specific distribution if you already know the specific shape of the column.
Searching through parametric distributions is faster that non-parametric distributions but can have lower accuracy. For the highest accuracy (that takes the longest amount of time) use the non-parametric gaussian_kde distribution.
When are the min/max and rounding schemes enforced?
Using these options will enforce the min/max values or rounding scheme when reverse transforming your data. Use these parameters if you want to recover data in the same format as the original.
When is it necessary to model missing values?
When setting the model_missing_values parameter, consider whether the "missingness" of the data is something important. For example, maybe the user opted out of supplying the info on purpose, or maybe a missing value is highly correlated with another column your dataset. If "missingness" is something you want to account for, you should model missing values.